Overview
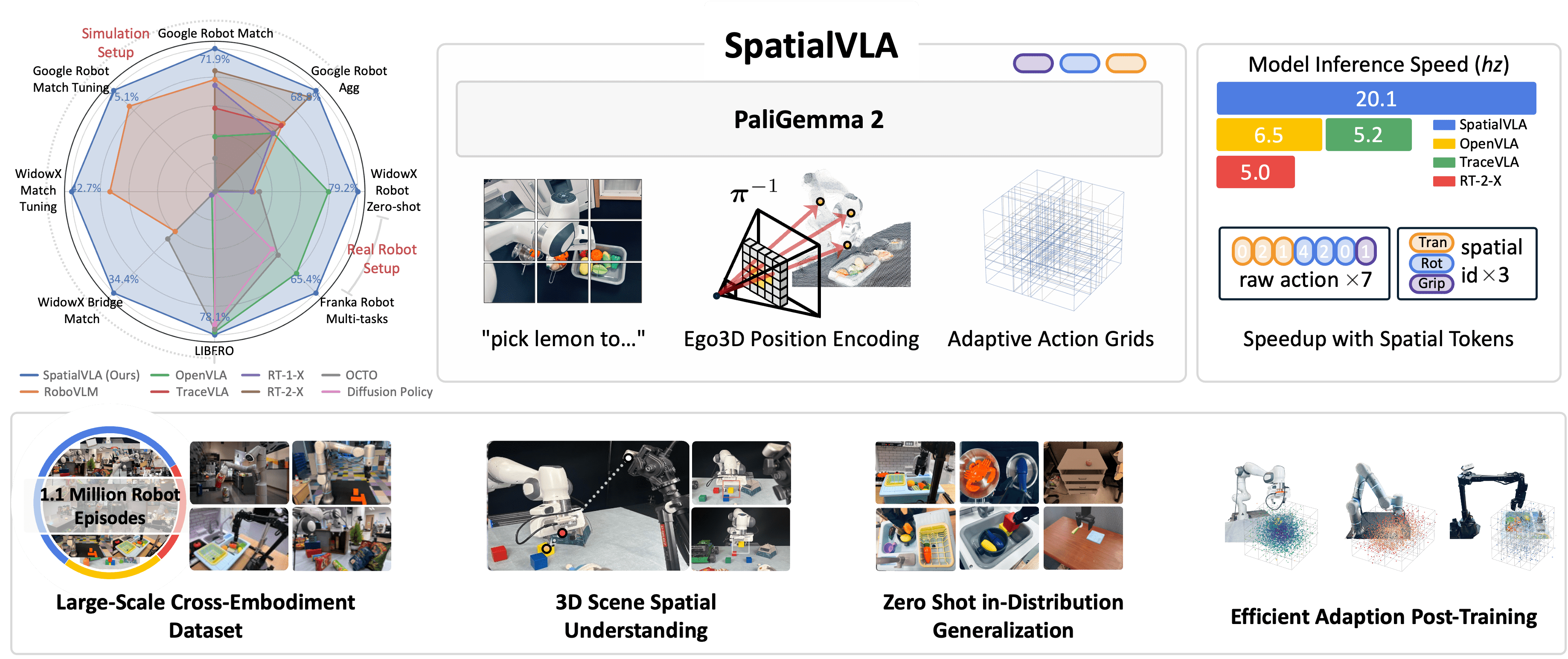
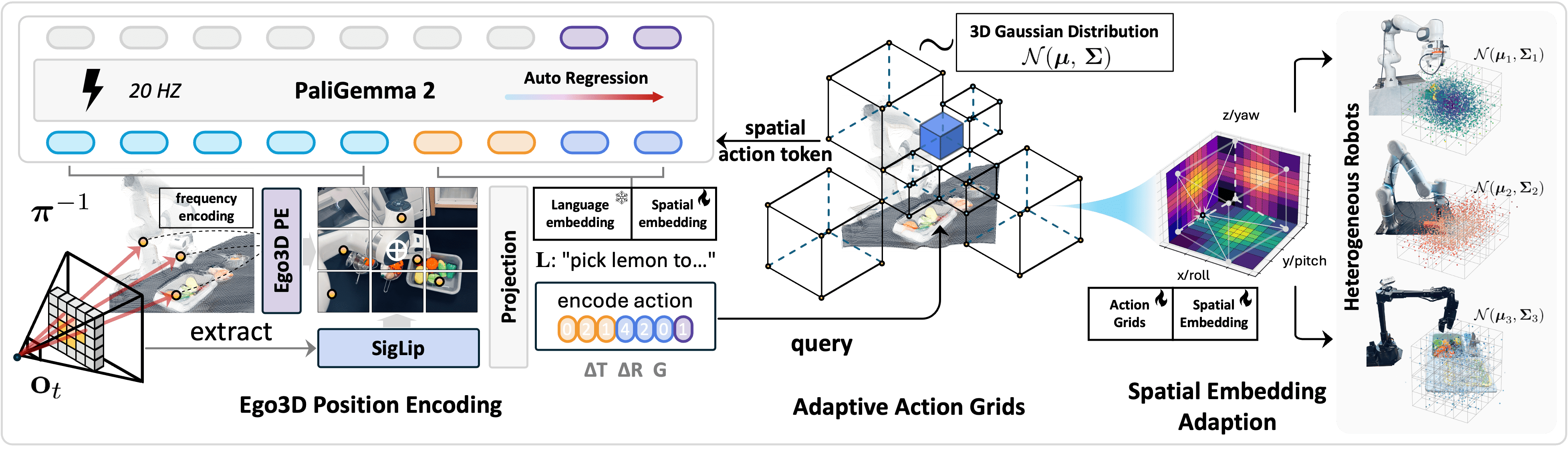
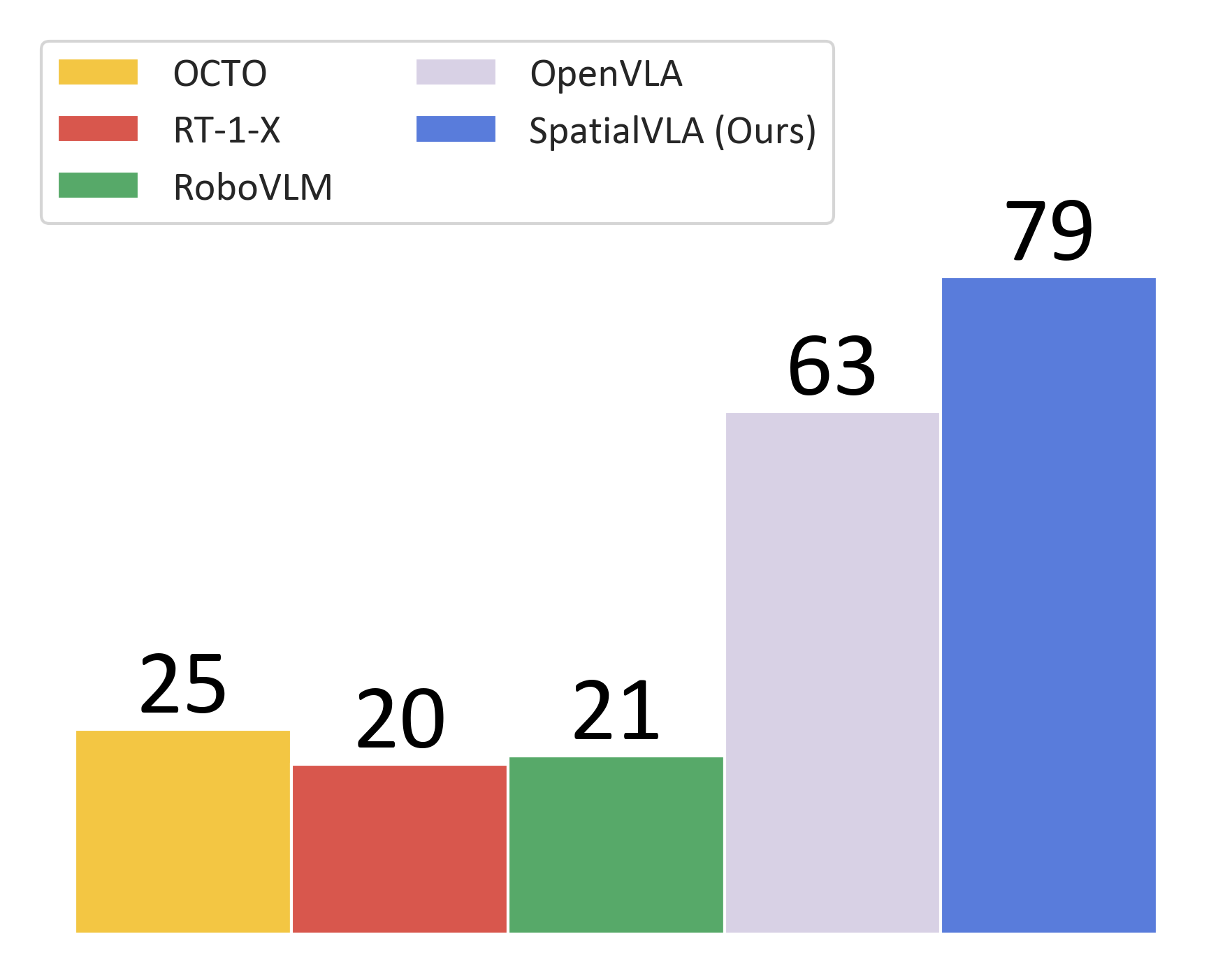
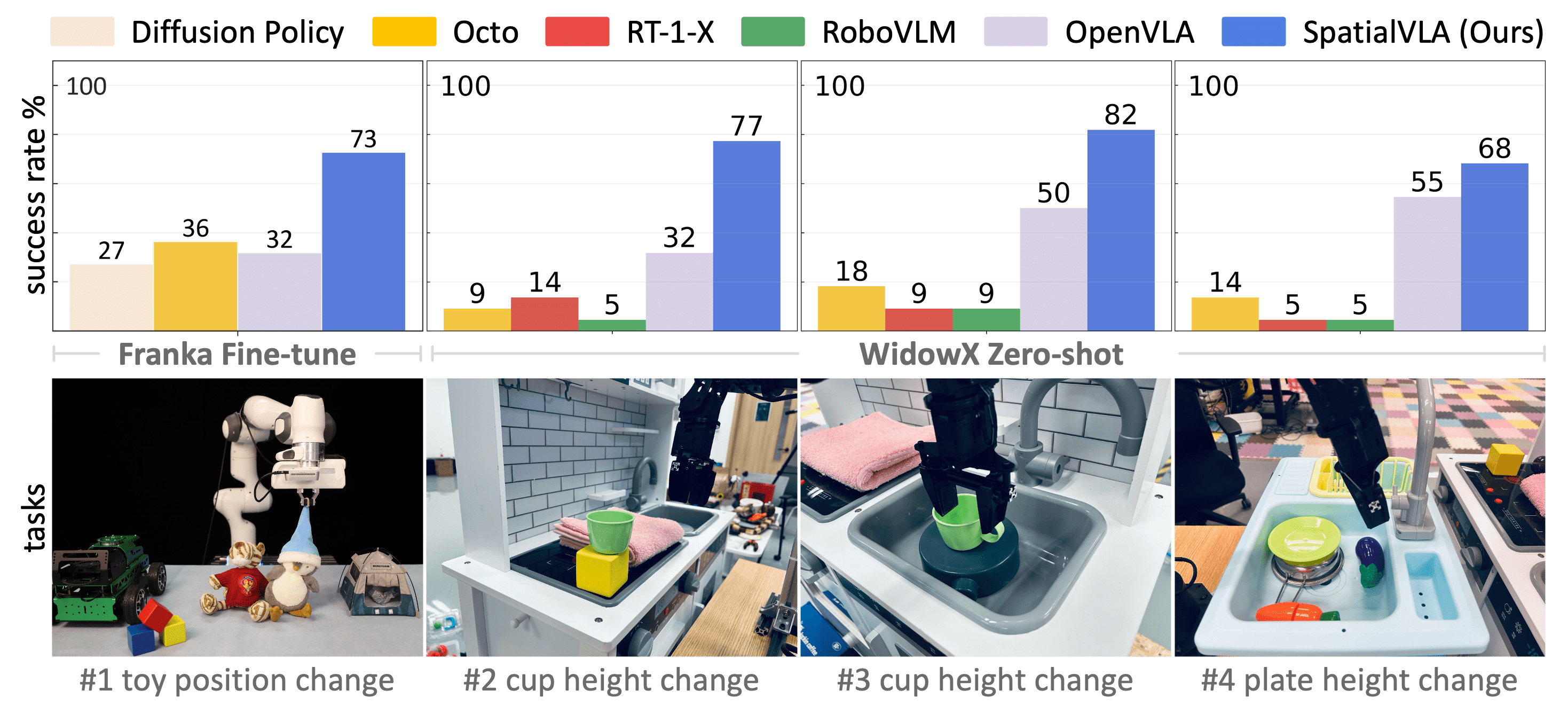
We present SpatialVLA, a spatial-enhanced vision-language-action model that is trained on 1.1 Million real robot episodes. The model is equipped with 3D Egocentric Position Encoding and Adaptive Spatial Grids to explore spatial representations for generalist robot policy, achieving superior 3D scene spatial understanding, zero-shot in-distribution generalization, and efficient adaption to new robot setups. The model achieves state-of-the-art performance across a diverse range of evaluations and shows significantly faster inference speed with less tokens per action.